
Python's bytes and strings
Python: strings and bytes
Python 3 is the new python, and python 2 should be regarded as legacy. But, it is still being used heavily and will likely live beyond its end of life. Recently, a project forced me to use python 2.7 within a Centos environment and I hit some small encoding issues.
Character Sequences
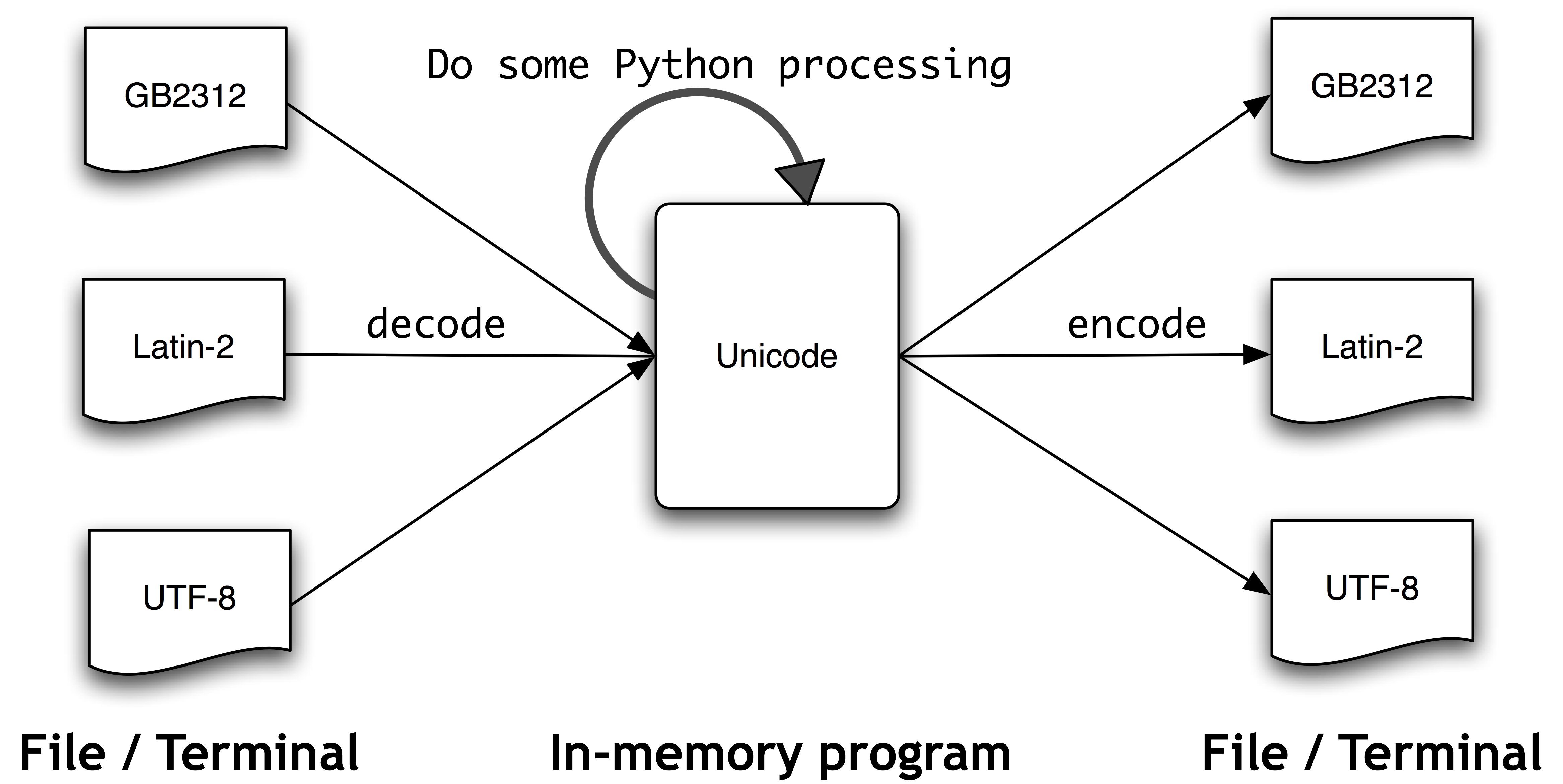
In python there are two types that represent sequences of characters:
Python 3
- Bytes: raw 8 bit values
- Strings: unicode characters
Python 2
- Strings: raw 8 bit values
- Unicode: unicode characters
Python 3’s strings and python 2’s unicode instances do not have binary encoding.
Therefore, the user must implement the conversion manually by encoding and
decoding the between binary and unicode.
It is important that when constructing our program to deal with conversion between these data types that it is done at the furthest boundaries of our interfaces. This is sometimes referred to as the ‘unicode sandwich’.
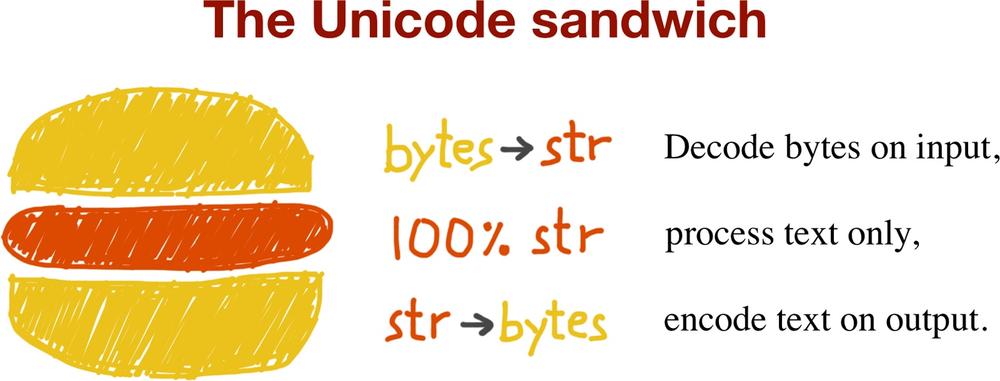
This guarantee’s a level of compliance when accepting alternate encodings and
a much stricter output encoding scheme - generally utf-8. We should not be doing
any encoding or decoding in the middle of our applications.
This is of particular importance when dealing with file operations that are not
text. In python 3, file operations do much of the encoding and decoding for you,
returning str instances on read and write. But, python 3 will use the system
default encoding where an encoding scheme is not specified. Much of the time
we will receive utf-8 but on some machines this is not guaranteed.
If your application is expected to work across multiple operating systems and/or
versions, you should set the encoding=<your-encoding type> keyword argument
manually to prevent hidden bugs in the future.
Subtle differences exist between python 2 and 3.
with open('encoding.txt', 'w') as f:
f.write(os.urandom(10))
In python 2 this will work as by default open use binary encoding. However, python 3
uses utf-8 instead. If we tried to run this it will raise a TypeError: must be str not bytes.
To make this work in both 2 and 3, we need to specify that it is binary.
with open('encoding.txt', 'wb') as f:
f.write(os.urandom(10))
Writing binary to a file must also be specified with rb instead of r.
with open('encoding.txt', 'rb') as f:
for line in f:
print(line)
Notable mentions
Other interesting points between python 2’s str and unicode, and python 3’s
str and bytes are how they are compared, or typed. In python 2, if a
str is ASCII (7-bits) it will pass an equality check with unicode characters.
They can also be combined using the + operator, and can be formatted using
%s string formatting.
a = 'a'
b = u'a'
a == b # true
c = a + b # u'aa'
print 'as str a,b =%s%s' % (a,b) # as str a,b=aa
This means that in python 2 we could pass unicode or a str instance and expect
the same result - if 7-bit ASCII. In python 3 str and bytes never cannot
pass equality checks, not even empty strings.
Summary
Legacy python is still a thing, so having an understanding of how the encoding
paradigms differ between each version is important. The differences in file operations
can have significant effects within your applications, and is quite prominent in
network level communications. Wherever possible work with str types inside
your main business logic to alleviate any nasty surprises further down the line.
And have a read over some these gems regarding utf-8, which I deliberately
did not go over in any detail.
references
Ned Batchelder’s How Do I Stop The Pain
Joel Spolsky’s The Absolute Minimum Every Software Developer Absolutely, Positively Must Know About Unicode and Character Sets (No Excuses!)
Keep up to date with my stuff
Subscribe to get new posts and retrospectives